- Published on
Full text search with Elasticsearch
Full text search with elastic search - Elasticsearch as a search engine
Many companies have thousands of documents that contain important information. In order to access this data, you must search through the documents manually. The search is very time-consuming. Especially when technical terms such as medical terms or terms with different spellings occur, searched information is often not found. Here we look at why search engines and enterprise search are becoming so popular in today's business world, as well as some of the benefits companies may expect from implementing enterprise search. In this example the search engine Elasticsearch is used.
What is Elasticsearch
Elasticsearch is
- a distributed search and also analytics engine
- a NoSQL database
- written in Java (based on Lucene like Solr)
- a scalable web application (simple RESTful interface) with a resilient architecture
- in the ELK stack (Elasticsearch, Logstash and Kibana)
The license model of Elasticsearch was changed and therefore Elasticsearch is not available as open source software. That's why the OpenSearch project was launched in 2021. As license OpenSearch chooses now as usual the open source license Apache 2.0.
RDBMS vs. Elasticsearch terminology
| Relational Database | Elsticsearch |
|---|---|
| Database | Index |
| Table | Type |
| Row | Document |
| Column | Field |
Example with dinosaurs
The scientific names of dinosaurs are difficult to learn. Some of them are spelled in an illogical maner (as occurred with the name Velociraptor), and if you're looking for an unusual dinosaur's name you will have troubles with finding similar sounding names. The problem with spelling can also be applied to medical names.
As an example and to show the possibilities of Elasticsearch, a search for dinosaurs will be implemented. With Elasticsearch analyzer and tokenizer a fault-tolerant full text search is made possible.
Create an index
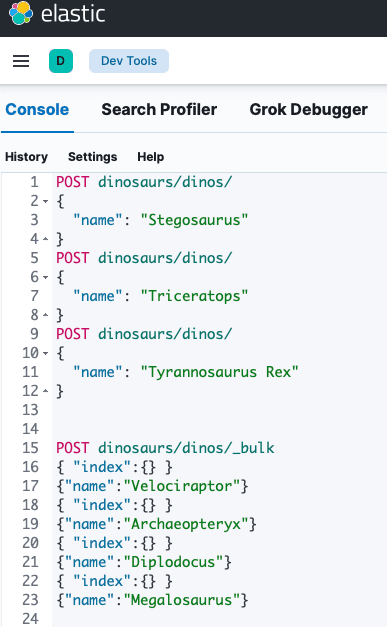
The index dinosaurs and the type dinos will be created with the following HTTP POST command
POST dinosaurs/dinos/
{
"name": "Stegosaurus"
}
POST dinosaurs/dinos/
{
"name": "Triceratops"
}
POST dinosaurs/dinos/
{
"name": "Tyrannosaurus Rex"
}
POST dinosaurs/dinos/_bulk
{ "index":{} }
{"name":"Velociraptor"}
{ "index":{} }
{"name":"Archaeopteryx"}
{ "index":{} }
{"name":"Diplodocus"}
{ "index":{} }
{"name":"Megalosaurus"}
Or you can create the index via curl
curl -XPOST
"http://my-search-server:9200/dinosaurs/dinos/" -H 'Content-Type: application/json' -d '
{
"name": "Stegosaurus"
}'
Searching with exact values
Get all dinosaurs
GET dinosaurs/_search
{
"query": {
"match_all": {}
}
}

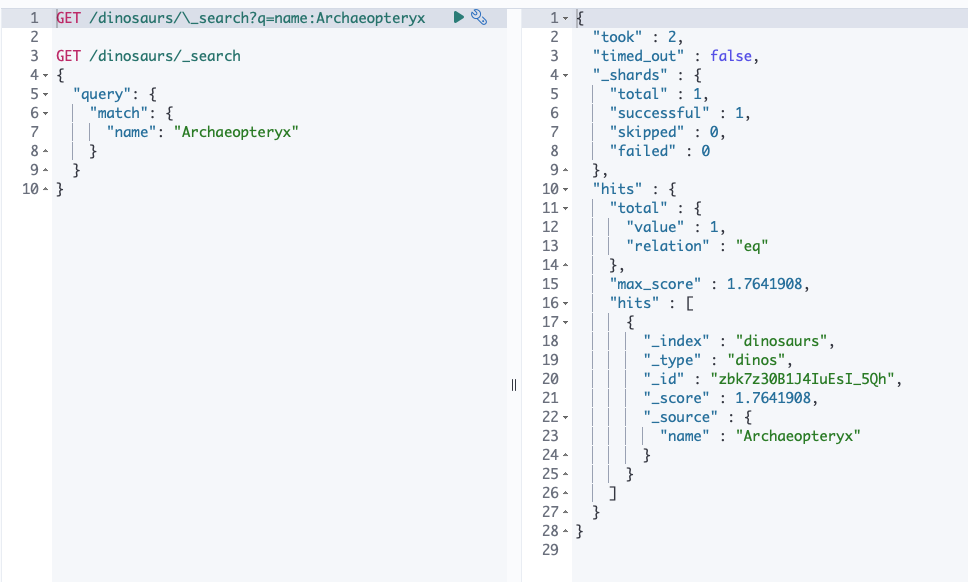
Get a dinosaur with given name Archaeopteryx
GET /dinosaurs/_search?q=name:Archaeopteryx
or
GET /dinosaurs/_search
{
"query": {
"match": {
"name": "Archaeopteryx"
}
}
}
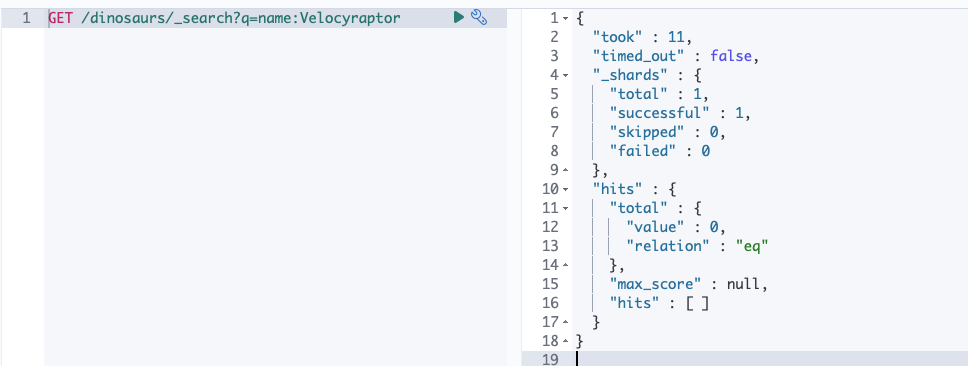
Fault-tolerant full text search (wrong spelling searching)
Search for Velociraptor with wrong spelling (Velocyraptor) returns no results.
GET /dinosaurs/_search?q=name:Velocyraptor
A search with wildcards can be helpful here. But you need to know where to place the wildcard (*).
GET /dinosaurs/_search?q=name:Velo*raptor
In order to find searched entries even without wildcards, the search index will be optimized with analyzers and tokenizers.
Mapping
Mapping is the process of defining how a document, and the fields it contains, are stored and indexed.
- Define how the fields of a document are stored and indexed
- Explicit mapping for field name
PUT /dinosaurs
{
"mappings": {
"dinos": {
"properties": {
"name": {
"type": "text",
"analyzer": "2_3_ngram_analyzer"
}
}
}
}
}
Analyzer and Tokenizer
Analyzer
Text analysis enables Elasticsearch to perform full-text search, where the search returns all relevant results rather than just exact matches. You can create your custom analyzer
Tokenizer
Analysis makes full-text search possible through tokenization: breaking a text down into smaller chunks, called tokens. In most cases, these tokens are individual words.
N-gram tokenizer for Velociraptor
- Ve, el, lo, oc, ci, ir, ra, ap, pt, to, or (bigram, 2-gram)
- Vel, elo, loc, oci, cir, ira, rap, apt, pto, tor (trigram, 3-gram)
PUT /dinosaurs
{
"settings": {
"analysis": {
"analyzer": {
"2_3_ngram_analyzer": {
"type": "custom",
"filter": "lowercase",
"tokenizer": "2_3_ngram_tokenizer"
}
},
"tokenizer": {
"2_3_ngram_tokenizer": {
"token_chars": [
"letter",
"digit",
"punctuation",
"symbol",
"whitespace"
],
"min_gram": "2",
"type": "ngram",
"max_gram": "3"
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "2_3_ngram_analyzer"
}
}
}
}
Now the search will work with wrong spelling.
GET /dinosaurs/_search?q=name:Velocyraptor
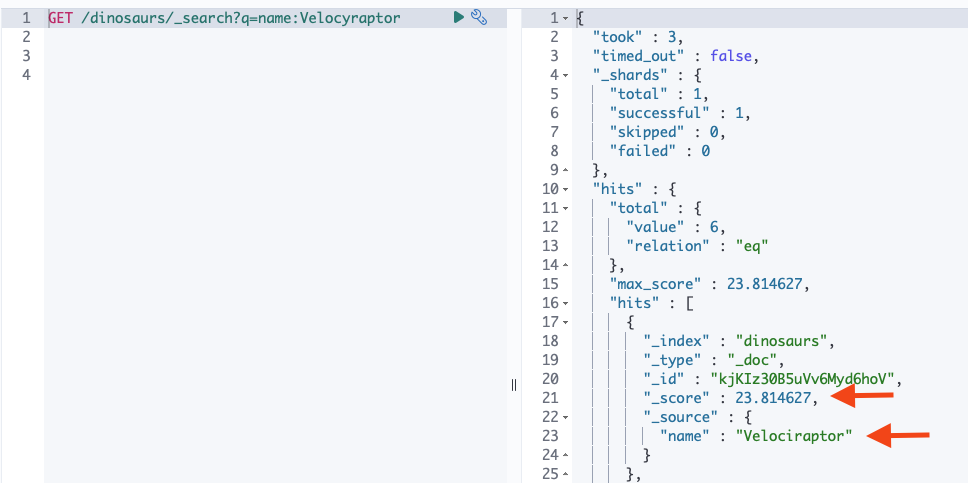
Now several results are displayed. The hits are weighted (hit score) according to importance.
Conclusion
In the example above complicated dinosaur names were used to show the design of the search index. Full text search is not as simple as it seems. It can be a hard task to find all the subtle variations of a word or phrase, including different spellings. Luckily, there are enterprise search solutions that cater to this need. Elasticsearch is one such enterprise search solution. A full text search solution needs to be intuitively designed so that the end user can easily find accurate content within the framework of a corporate intranet.